Intelligence des documents
Êtes-vous un organisme ou gouvernement avec des données que vous croyiez structurées, mais qui ne le sont finalement pas tant que ça?

consultation, rédaction, recherche et développement | technologies sobres | intelligence naturelle
Êtes-vous un organisme ou gouvernement avec des données que vous croyiez structurées, mais qui ne le sont finalement pas tant que ça?
Êtes-vous une collectivité qui veut rendre vos données géomatiques et réglementaires accessibles, compréhensibles et utiles au public ou même simplement à vous-même?
Êtes-vous une communauté linguistique minoritaire? Avez-vous besoin de modèles et d’outils pour documenter, enseigner, et faire vivre votre langue à l’ère numérique?

30 avr. 2026
Pour plusieurs raisons, je suis en train de quitter GitHub depuis quelques mois. Je n’irai pas trop dans le détail, surtout parce que ce billet de blogue décrit pas mal mon parcours, et je crois, celui de plusieurs autres participants au mouvement du logiciel libre.
[lire la suite]6 avr. 2026
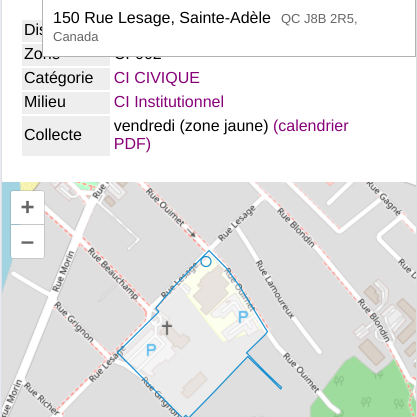
Si vous cherchez à mieux comprendre le règlement d’urbanisme de votre ville, il est très utile d’avoir une carte interactive du zonage. C’est pour ça que, lorsque j’ai été élu au conseil à Sainte-Adèle, j’ai crée ZONALDA. Cet article explique comment en trouver ou créer la base de données géomatiques pour une telle application. [lire la suite]
25 févr. 2026
Si vous voulez fouiller dans un PDF pour en extraire des metadonnées, des images, et même du texte, j’ai des superbes logiciels libres pour vous: PLAYA-PDF et PAVÉS. Et si vous avez besoin d’un consultant pour vos besoins d’intelligence documentaire je suis disponible pour des contrats! [lire la suite]
Formé d‘abord en linguistique, je cumule plus que 25 ans d’expérience professionnelle en traitement automatique du langage naturel et compréhension de la parole. En cours de route, j’ai développé des compétences diversifiées en informatique, surtout dans le domaine du logiciel libre, en tant que chargé d’entretien et collaborateur sur divers projets.