Document Intelligence
Are you a government or organization that depends on semi-structured data, which, in the end, are not very structured at all?

consulting, writing, research, and development | low-tech solutions | human intelligence
Are you a government or organization that depends on semi-structured data, which, in the end, are not very structured at all?
Are you a provider of public data that wants to make these data actually accessible, understandable, and useful to the public?
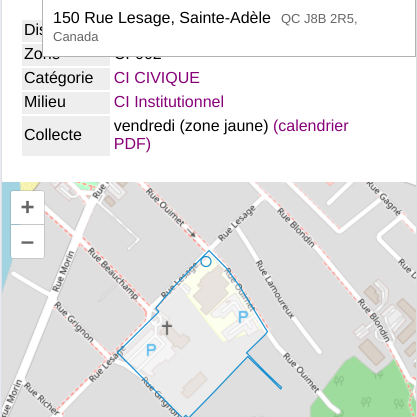
Are you a minority language community in need of models and tools to document, teach, and revitalize your language in the digital world?

Apr 30, 2026
I had been trying for some time, to get Mastodon to display preview images for my blog posts. It seemed to me that all I had to do was add the proper OpenGraph og:type, og:title, and og:image tags, right? As it turns out, not quite, no… It’s important to actually read the specification!
[read more]
Apr 21, 2026
Say you have a corporate surplus small-form-factor PC from the 2010s. Maybe you have several! You have no desire to converse with the fake machine god that will supposedly kill us all, but at the same time, you’ve heard that recent VLMs are remarkably good at OCR and other actually useful information extraction tasks. Can you run them on your Compaq Elite 8100? Why yes, you can! [read more]
Feb 25, 2026
If you need to delve into the murky depths of a PDF to return with
spices and silk extract metadata, images, and yes, even text, I
have some excellent Free Software for you:
PLAYA-PDF and
PAVÉS. If you’d like to know how
this came to be, then continue reading. And if you need a consultant
for document intelligence tasks, large and small, I’m currently
available for contracts of all sorts!
Originally trained in linguistics, with over 25 years of experience in speech and natural language processing technology, I have also developed a wide range of expertise in open-source software development, as a maintainer and valued contributor to numerous projects.