mardi 14 janvier 2025
Comme mentionné dorénavant, le format PDF est un format
de présentation, à la différence du HTML par exemple, qui sépare dans
la mésure du possible la structure sémantique du texte et sa mise en
page. Concrètement cela veut dire que, en théorie (on aimerait tous y
vivre!), l’extraction du texte même d’une page HTML très « visuelle »,
avec une mise en page comprenant des multiples colonnes, des images,
des figures, etc, se résume à simplement enlever les tags.
Comme aussi mentionné dorénavant, le standard PDF dans sa
déclinaison « universellement
accessible »
admet une extraction du texte et même de la structure sémantique
légèrement plus compliquée mais néanmoins faisable. Malheureusement,
il suffit qu’on oublie de cocher la case PDF/UA en sauvegardant un
fichier, ou qu’on sélectionne « imprimer en format PDF » au lieu de
« exporter », ou qu’on passe le PDF par un logiciel douteux, pour que
toute cette belle structure tombe à l’eau. On se retrouve avec des
fragments de texte positionnés absolument, souvent sans séparation
entre les mots et parfois même dans une ordre arbitraire.
Dont la nécessité d’une analyse de la mise en page, pour identifier et
séparer le texte, les figures, et les tableaux, mais aussi pour
identifier les éléments textuelles, dont les titres et listes, ainsi
que les artéfacts textuelles qui ne font pas partie du contenu, dont
les en-têtes, les pieds de page et les captions de figures. Étant
donné le fait que les éléments d’un PDF sont positionnés absolument
sur une page (sans référence à une grille ou autre structure
visuelle), la diversité de formats de papier, de polices de
caractères, de marges et entrelignes, entre autres, il est presque
impossible de concevoir des règles pour prendre en charge tout cela à
moins de le refaire pour chaque nouveau document ou presque.
Dont aussi la nécessité (il me semble que je me répète souvent!)
d‘utiliser… l’apprentissage machine (toé IA chose machin). On en a
déjà parlé un peu par rapport aux éléments du texte. On
peut catégoriser les types d’analyses propices à l’apprentissage.
Analyse textuelle
Ceci est le type d’analyse le plus simpliste et probablement le plus
répandu. En présumant une extraction préalable du texte,
correspondant le plus possible à la forme perçue par un lecteur, on
peut faire une analyse textuelle (parsing) ou une classification
de séquence pour répérer des éléments structurels.
Évidemment, puisque toute l’information provenant de la mise en page a
été évacué par le processus d’extraction de texte, on n’a peu de
chances de reconstruire la structure du document de façon robuste ou
fiable.
Analyse espacielle
Par défaut, ALEXI fait une
analyse espacielle, c’est à dire qu’il prend compte de l’emplacement
des éléments de texte ainsi que des attributs typographiques (taille
de police, caractères gras ou italiques, etc.) pour identifier des
éléments tels que titres de sections, éléments de listes, etc.
Bien qu’il utilise l’apprentissage machine, d’autres logiciels
utilisent aussi des méthodes algorithmiques ou heuristiques, par
exemple pdfminer.six ou
camelot.
Analyse visuelle
Dernièrement, il existe une tendance à faire une analyse purement
visuelle de la mise en page pour identifier les éléments
structurelles. Alors que l’analyse textuelle évacuait toute la mise
en page et les attributs visuels du document, une analyse visuelle
fait exactement le contraire - chaque page d’un PDF est transformé en
image matricielle, qui est par la suite analyser par un modèle de
vision tel que
DeformableDETR,
YOLOX ou
YOLO, qui a été
préalablement entraîner sur un corpus d’images semblables.
Quoiqu’il soit possible d’utiliser ces modèles par le biais de des
logithèques peu fiables provenant de compagnies qui préfèrent prendre
votre argent et/ou vos données personnelles, ceci n’est aucunement
nécessaire. En plus, il semble que ces logithèques libres
fonctionnent essentiellement comme appât pour les services payants /
espions. Nous allons donc, dans le prochain billet, regarder comment
utiliser les modèles directement pour éviter divers problèmes reliés à
ces logithèques.
(La seule exception dans cette bande là est probablement
DocLing qui provient d’un groupe
de récherche réputé.)
jeudi 17 octobre 2024
À quoi ça sert, au juste, tout cet effort
d’analyse des fichiers PDF? D’abord, bien
sûr, ça facilite la recherche, telle qu’implémentée dans
SÈRAFIM (un SystÈme de
Recherche Ad-hoc pour Fouiller dans les Informations
Municipales) puisqu’on est capable d’indexer chaque article et
chapitre individuellement - on peut ainsi comparer les dispositions
par rapport aux piétons dans l’aménagement des
stationnements
à travers quelques villes des Laurentides, par exemple.
Mais pas juste ça! Le fait d’avoir extrait les unités semantiques des
règlements nous permet d’ajouter plusieurs fonctionnalités pour en
faciliter la lecture et la compréhension, dont:
- L’ajout d’hyperliens. Par exemple, dans l’article
264
du règlement de zonage de Sainte-Adèle, on peut maintenant naviguer
vers le règlement de
construction
cité là-dedans ainsi que l’article
251
sur les aménagements piétonniers.
- La navigation structurée en-ligne. Au lieu d’avoir besoin de
télécharger le PDF pour trouver un chapitre ou section spécifique,
on peut voir tous les règlements dans une
arborescence et
expansionner pour obtenir rapidement le contenu recherché. Des
hyperliens vers la page spécifique du PDF sont aussi fournis.
- Mais surtout, ça nous permet d’utiliser… 🎉des grands modèles de
langage🎆
(oui, ces célèbres patentes qu’on appelle à tort de l’intelligence
artificielle) pour en faire des analyses automatiques, des résumés,
et d’autres manipulations.
L’analyse spécifique qu’on en fera ici est une analyse du plus proche
voisin
qui nous permettra de faire de façon plus efficace une analyse du type
mentionné ci-haut, c’est à dire, répondre à des questions du genre
«comment se comparent les dispositions par rapport à l’aménagement des
-stationnements entre Sainte-Adèle, Saint-Sauveur et Prévost». (si cela
vous semble une question hautement inutile, vous n’êtes sûrement pas
le public cible de ce blogue)
Pour ce faire, nous utiliserons la célèbre (ou pas) logithèque
SentenceTransformers pour calculer des
réprésentations vectorielles (embeddings) correspondant à chaque
unité sémantique dans l’ensemble des règlements. Par la suite, on
peut utiliser une multiplication matricielle très rapide pour obtenir
les proches
voisins
de chaque élément (c’est à dire les articles semblables dans d’autres
règlements ou d’autres villes). C’est vraiment très simple et
efficace! Par contre, pour des très grands corpus de documents, il
sera nécessaire d’utiliser un outil de référencement optimisé tel que
FAISS ou
RAGatouille.
Préalablement on aura téléchargé un ensemble de règlements avec
ALEXI. Pour faciliter la chose
on se limitera à trois règlements de zonage:
Les ayant téléchargés, on va les analyser avec ALEXI:
alexi extract *.pdf
Cela va prendre quelques minutes pour créer le répertoire export
avec plein de fichiers HTML et JSON (si vous voulez avoir plus
d’information sur ce qui se passe vous pouvez utiliser alexi -v extract *.pdf). Par exemple, on voit que tous les articles du
règlement de zonage de Sainte-Adèle se trouvent maintenant sous
export/Rgl-1314-2021-Z-en-vigueur-20240823/Article, chacun dans un
répertoire avec un seul fichier index.html.
Le texte des unités sémantiques est maintenant converti d’une forme
graphique (des PDF) vers une forme moyennement sémantique (du HTML).
Ce qui nous intéresse, par contre, c’est le texte brut. On peut alors
utiliser BeautifulSoup ou
lxml pour l’extraire de nouveau et le
passer dans le modèle SentenceTransformers:
from bs4 import BeautifulSoup
def get_text(path) -> str:
with open(path) as infh:
soup = BeautifulSoup(infh)
return soup.article.text
articles = {path : get_text(path) for path
in Path("export").glob("**/Article/*/*.html")}
Réprésentation vectorielle et proches voisins
Pour générer les réprésentations vectorielles (embeddings) il nous
faut un modèle pré-entraîné. Il en existe plusieurs sur le site
HuggingFace qui sont spécialisés pour le français, qu’on retrouve
(avec plusieurs informations utiles sur leur performance) dans
l’espace
DécouvrIR.
Pour notre démonstration on utilisera la variété le plus simple et
rapide, un «Single-vector dense bi-encoder» de moins de 100M
paramètres. En cochant les cases on trouve que le meilleur à date est
biencoder-distilcamembert-mmarcoFR… on
y va!
import sentence_transformers as st
model = st.SentenceTransformer("antoinelouis/biencoder-distilcamembert-mmarcoFR")
Il nous reste qu’à transformer (lolle) les textes extraits en vecteurs
ou plus précisément en une matrice. Pour ce faire on va les énumérer
et retenir les indices pour faire la correspondance entre documents et
rangées de cette matrice:
artidx = {path: idx for idx, path in enumerate(articles)}
idxart = list(articles)
Par la suite on calcule les vecteurs:
embeddings = model.encode(list(articles.values()), convert_to_tensor=True,
show_progress_bar=True)
Sur une carte graphique GT1030, qu’on peut acheter usagée autour de 75
$, cela prend environ 30 secondes. Enfin, on utilise la fonction
semantic_search pour trouver les plus proches voisins de chaque
rangée de la matrice (c’est instantané):
neighbours = st.util.semantic_search(embeddings, embeddings, top_k=20)
Pour voir ce que cela donne pour l’article
264
mentionné ci-haut, on va trouver le vecteur correspondant à cet
article, puis ensuite afficher les plus proches articles qui ne
viennent pas du même règlement:
import textwrap
# la rangée qui correspond à l'article 264 du règlement 1314-2021-Z
srcpath = Path("export/Rgl-1314-2021-Z-en-vigueur-20240823/Article/264/index.html")
idx = artidx[srcpath]
for n in neighbours[idx][1:]:
neighbour_idx = n["corpus_id"]
dstpath = idxart[neighbour_idx]
if dstpath.parts[1] == srcpath.parts[1]:
continue
print(idxart[neighbour_idx])
print(textwrap.fill(articles[idxart[neighbour_idx]].strip()[0:250]), "...")
print()
On voit que le modèle a bel et bien trouvé des articles pertinents:
export/RUD_T6_VR/Article/6.4.6.3/index.html
Article 6.4.6.3 Aménagement d’une aire de stationnement extérieure de
15 cases ou plus En plus des dispositions de l’article précédent, les
dispositions suivantes s’appliquent à toute aire de stationnement de
15 cases ou plus. L’aménagement d’une ai ...
export/RUD_T6_VR/Article/6.4.6.4/index.html
Article 6.4.6.4 Aménagement d’une aire de stationnement extérieure de
100 cases ou plus En plus des dispositions des articles précédents,
une aire de stationnement pour véhicule de 100 cases et plus doit
respecter les dispositions suivantes : 1° une ...
export/RUD_T6_VR/Article/6.4.9.1/index.html
Article 6.4.9.1 Nombre de cases de stationnement pour véhicule
automobile Tous les usages principaux doivent disposer d’un
stationnement hors rue d’une capacité minimale et maximale conforme
aux dispositions du présent article. Cette exigence est co ...
export/RUD_T6_VR/Article/6.4.5.1/index.html
Article 6.4.5.1 Aménagement d’une aire de stationnement extérieure de
moins de 3 cases ou allée de stationnement Une aire de stationnement
extérieure de moins de 3 cases ou une allée de stationnement doit
respecter les dispositions suivantes : 1° el ...
export/Reglement-2009-U53-fevrier-2024/Article/12.1.7/index.html
Article 12.1.7 Accès aux aires de stationnement (modifié, règlement
numéro 2011-U53-18, entré en vigueur le 2011-07-21) (modifié,
règlement numéro 2011-U53-21, entré en vigueur le 2011-12-15) Toute
case de stationnement doit être implantée de telle ...
Ce qu’on voit aussi est que la plupart des articles les plus
similaires viennent du règlement de Prévost. Ceci nous indique que le
règlement de zonage de Prévost (2024) serait plus similaire à
celui de Sainte-Adèle que celui de Sainte-Agathe (2009).
Recherche semantique
Bien sûr, rien nous empêche de comparer autre chose que des articles
des règlements. On peut également convertir des questions ou d’autres
documents en vecteurs. Si par exemple on voulait savoir quelles
articles ressemblent aux normes proposées par le CRE Montréal pour le
stationnement écoresponsable en matière de
verdissement… on
peut le faire! Il faut simplement télécharger et extraire le texte de
cette page:
import requests
r = requests.get("https://reglementaction.com/verdissement-du-stationnement/")
soup = BeautifulSoup(r.content)
Puis le transformer avec le modèle et faire semantic_search sur les
règlements:
tvec = model.encode(soup.text)
for n in st.util.semantic_search(tvec, embeddings)[0][0:4]:
neighbour_idx = n["corpus_id"]
score = n["score"]
print(score, idxart[neighbour_idx])
print(textwrap.fill(articles[idxart[neighbour_idx]].strip()[0:500]), "...")
print()
Et on trouve des dispositions potentiellement intéressantes dans les règlements:
0.413027286529541 export/Rgl-1314-2021-Z-en-vigueur-20240823/Article/188/index.html
Article 188 Compensation de la surface végétalisée minimale par des
espaces de stationnements perméables La surface d’une portion d’un
espace de stationnement situé à l’intérieur du périmètre urbain conçu
à l’aide de pavés alvéolés ou de gazon renforcé avec dalle alvéolée
peut être comptabilisée dans le calcul de la surface végétale minimale
par un ratio de 50% (exemple : 100 m2 de stationnement en dalle
alvéolé peut donc représenter un crédit de 50 m2 de surface
végétalisée). La surface ainsi ...
0.38985273241996765 export/Rgl-1314-2021-Z-en-vigueur-20240823/Article/267/index.html
Article 267 Ilot de verdure Un espace de stationnement hors rue
extérieur comportant 20 cases ou plus doit être aménagé de façon à ce
que toute série de 20 cases de stationnement adjacentes soit isolée
par un îlot de verdure conforme aux dispositions suivantes : Un îlot
de verdure doit respecter les dimensions suivantes : une largeur
minimale de 2 mètres; une superficie minimale de 25 mètres carrés pour
les cases aménagées en rang double, soit dos-à-dos; une superficie
minimale de 13 mètres car ...
0.3851878046989441 export/RUD_T6_VR/Article/6.1.2.6/index.html
Article 6.1.2.6 Agrandissement majeur d’un bâtiment Un agrandissement
majeur représentant 25 % ou plus de la superficie de plancher du
bâtiment principal, mais moins de 100 % de cette superficie peut être
réalisé malgré l’existence d’un aménagement d’une aire de
stationnement dérogatoire pourvu que les conditions suivantes soient
respectées : 1° dans le cas d’une aire de stationnement extérieure de
15 cases et plus, l’aire de stationnement doit être réaménagée de
manière à respecter les exigenc ...
0.3690324127674103 export/RUD_T6_VR/Article/6.4.4.1/index.html
Article 6.4.4.1 Revêtement d’une aire de stationnement Une aire de
stationnement extérieure doit être recouverte par l’un des matériaux
de revêtement suivants qui peuvent être perméables ou non, le cas
échéant : 1° l’asphalte; 2° le béton; 3° le pavé d e béton; 4° le pavé
de béton avec alvéoles végétalisées ou remplies de poussières de roche
ou de pierres concassées. Une aire de stationnement située dans une
zone de type T1, T2 ou ZP.1 et ZP.3 peut être recouverte de gravier. ...
On peut également extraire les règlements modèles de la page et
chercher les articles similaires (ce qui marche mieux lorsqu’on a une
plus grande collection de règlements).
Conclusion
J’ai fait un survol très rapide de ce qu’on est capable de faire avec
une extraction sémantique et structurée du texte d’un PDF de
règlement, et comment c’est facile de faire des analyses en utilisant
SentenceTransformers.
Dans des futurs billets on regardera l’agglomération des articles, la
possibilité d’entraîner un modèle spécifique pour ce domaine, ainsi
que la possibilité de faire une comparaison quantitative entre
règlements pour des critères spécifiques par rapport à
l’environnement.
mardi 15 octobre 2024
Ce billet présente une module d’extraction
d’information pour les règlements
municipaux en format PDF, qui sert à alimenter un moteur de récherche.
Il est la troisième partie d’une série de billets qui détaillent la
conception et implémentation de celle-là.
Oui, ça fait longtemps depuis le dernier billet! Il y en aura un
autre plus étoffé mais pour le moment je voulais juste ajouter
quelques notes.
Bien que le format PDF soit utilisé très largement pour stocker,
archiver, et distribuer des documents textuels, il est très important
de comprendre qu’il est d’abord un format de présentation. Il n’y a
aucune garantie que les objets
textuels
trouvées dans un PDF correspondent à des mots, phrases, ou alinéas
d’une langue naturelle - par exemple, chaque caractère peut bien être
représenté individuellement, ou des mots peuvent être scindés entre
deux lignes, et ainsi de suite.
Par contre, il existe des fonctions dans le standard
PDF qui
permettent de superposer une structure logique par-dessus la
présentation. C’est d’ailleurs ce qui permet un lecteur PDF de
présenter une table des matières dans la barre latérale. Dans le cas
où cette structure existe, on n’a qu’à l’utiliser… euh, non.
Le problème est, très évidemment, que rien n’oblige l’auteur d’un PDF
ni son outil de réaction d’inclure cette structure logique, ni de la
spécifier de façon prévisible et consistante. Par exemple, si on
compare la structure (avec pdfplumber --structure-text ou pdfinfo -struct-text) des règlements
1314-2021-DM
et
1328,
on voit que les énumérations sont tantôt exprimées (correctement) avec
des éléments LI, tantôt avec des éléments H5:
H5 (block)
"5. Lorsque deux dispositions ou plus du présent règlement s’appliquent...
L (block):
/ListNumbering /LowerAlpha
LI (block)
LBody (block)
"a. La disposition particulière prévaut sur la disposition générale; "
ou avec des LI seulement:
P (block)
"Les fins municipales pour lesquelles un immeuble peut être acquis par...
P (block)
" "
L (block):
/ListNumbering /Decimal
LI (block)
LBody (block)
"1. Habitation; "
Si on regarde le règlement de zonage, c’est dix fois pire, tout se
trouve dans des L imbriqués à perte de vue!
Aussi, une fois qu’on a compris et correctement interpreté le très
compliqué
standard
pour indiquer la structure logique d’un PDF (ce que ne font que
partiellement les logiciels libres de PDF, à moins qu’on ait le goût
de s’inféoder à Adobe), il reste qu’on doit encore extraire et traiter
le contenu.
Finalement, rien n’assure que la structure sera présent à travers
multiples versions d’un document, puisque le fonctionnaire qui génère
le PDF doit se rappeler de cocher la case “Tagged PDF” ou “PDF/UA” en
le faisant et ne pas simplement “imprimer en format PDF”, et parce que
des outils de manipulation de fichiers PDF ont tendance à omettre la
structure lors des transformations.
Pour cette raison non seulement est-il impossible de se fier
complètement à la structure logique d’un PDF, mais il est aussi
dangereux même de l’utiliser pour alimenter un modèle
probabilistique. La démarche plus robuste est d’entraîner deux
modèles, l’un avec les traits structurels et l’autre sans, et choisir
le plus approprié selon la présence de structure ou pas.
Annotation des données (la suite)
À date, je n’ai jamais réussi à trouver un logiciel libre potable pour
faire l’annotation de séquences ou étendues de texte, peut-être parce
que l’annotation est un marché très lucratif - sans annotation, il n’y
a aucune « intelligence » artificielle après tout!
Le plus promettant qui existe est
Doccano mais j’avais jugé qu’il
prendrait trop de travail pour l’adapter au cas d’usage particulier
pour quelques raisons:
- Il est conçu pour annoter du texte
brut
ou des images
individuelles.
Soit on perdrait la mise en page, soit le travail deviendrait ardu à
force d’annoter des centaines de pages individuellement.
- Il faudrait convertir les données dans son format préféré puis
reconvertir les annotations à la sortie pour les aligner sur les
données extraites du PDF.
- Son
architecture
est quand même assez complexe alors qu’on a vraiment juste besoin de
mettre des catégories sur des lignes dans un fichier CSV…
Heureusement il existe un outil bien adapter pour l’annotation de CSV,
qui s’appelle tantôt LibreOffice
Calc, tantôt Microsoft
Excel, blanc bonnet, bonnet blanc… ça marche vraiment très bien
puisqu’il se rappelle des valeurs qu’on rentre dans une colonne, alors
une fois les tags (étiquettes) rentrés on n’a que taper quelques
lettres, puis on peut étendre une tag pour couvrir un segment entier
de texte en glissant la souris, par exemple:
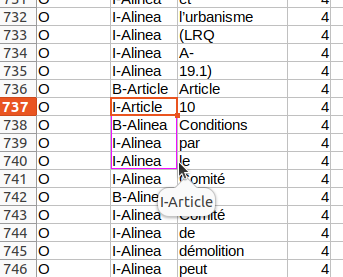
Ce qu’il est important de comprendre, par contre, c’est que en tant
qu’application de fiche de calcul, Calc (et Excel aussi) ont tendance
a “interpreter” les données dans un CSV de façon inattendue. Alors,
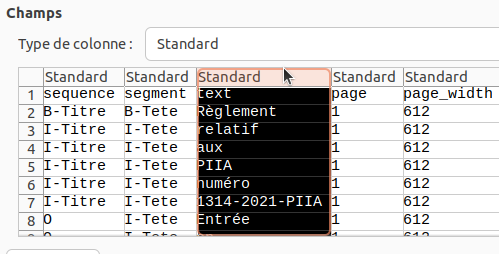
il faut absolument, lors de l’ouverture d’un fichier CSV, s’assurer
dans le dialogue de conversion, que:
- Le jeu de caractères est réglé sur “UTF-8”
- Le type de colonne pour la colonne “text” est réglé à “Texte”
Pour ce faire, il faut dans le dialogue de conversion sélectionner la
colonne en cliquant sur son titre:
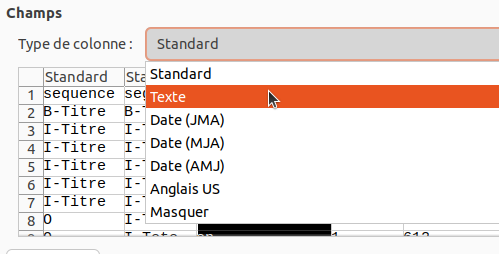
Puis sélectionner “Texte” dans le menu d’options:
Annotation et Correction avec ALEXI
Avec ALEXI on peut générer un CSV
de cette sorte pour une ou toutes les pages d’un PDF. Si par exemple,
on voudrait adapter le modèle d’extraction au nouveau règlement
d’urbanisme
durable
de la ville de Prévost, la procédure est:
- Télécharger le PDF (bien sûr) - par exemple (mon préféré) le titre
6: Mobilité durable et stationnement
écologique.
- Extraire un CSV préliminaire avec
alexi annotate RUD_T6_VR.pdf T6. Ceci créera les fichiers T6.pdf et T6.csv - le premier
est une version du PDF original marqué avec des rectangles colorés
pour les éléments (alinéas, titres, items) identifiés dans le
texte, alors que le deuxième est la réprésentation CSV.
- Ouvrir le CSV dans un logiciel de fichier de calcul et corriger les
annotations en suivant la démarche ci-haut.
Pour revoir l’effet de changer le CSV sur les annotations, il suffit
de rouler de nouveau la commande alexi annotate mais avec le CSV
corrigé: alexi annotate --csv T6.csv RUD_T6_VR T6. On peut
également extraire le document avec les nouvelles annotations en
utilisant alexi export -o T6-html T6.pdf puis voir le HTML extrait
en partant de T6-html/index.html.
Dans un prochain billet, nous allons regarder le processus
d’identification des éléments du texte ainsi que l’entraînement de
modèles en intégrant les annotations corrigées.