Notes sur l'extraction des PDF
Ce billet présente une module d’extraction d’information pour les règlements municipaux en format PDF, qui sert à alimenter un moteur de récherche. Il est la troisième partie d’une série de billets qui détaillent la conception et implémentation de celle-là.
Oui, ça fait longtemps depuis le dernier billet! Il y en aura un autre plus étoffé mais pour le moment je voulais juste ajouter quelques notes.
Au sujet du format PDF et de la structure logique
Bien que le format PDF soit utilisé très largement pour stocker, archiver, et distribuer des documents textuels, il est très important de comprendre qu’il est d’abord un format de présentation. Il n’y a aucune garantie que les objets textuels trouvées dans un PDF correspondent à des mots, phrases, ou alinéas d’une langue naturelle - par exemple, chaque caractère peut bien être représenté individuellement, ou des mots peuvent être scindés entre deux lignes, et ainsi de suite.
Par contre, il existe des fonctions dans le standard PDF qui permettent de superposer une structure logique par-dessus la présentation. C’est d’ailleurs ce qui permet un lecteur PDF de présenter une table des matières dans la barre latérale. Dans le cas où cette structure existe, on n’a qu’à l’utiliser… euh, non.
Le problème est, très évidemment, que rien n’oblige l’auteur d’un PDF
ni son outil de réaction d’inclure cette structure logique, ni de la
spécifier de façon prévisible et consistante. Par exemple, si on
compare la structure (avec pdfplumber --structure-text ou pdfinfo -struct-text) des règlements
1314-2021-DM
et
1328,
on voit que les énumérations sont tantôt exprimées (correctement) avec
des éléments LI, tantôt avec des éléments H5:
H5 (block)
"5. Lorsque deux dispositions ou plus du présent règlement s’appliquent...
L (block):
/ListNumbering /LowerAlpha
LI (block)
LBody (block)
"a. La disposition particulière prévaut sur la disposition générale; "
ou avec des LI seulement:
P (block)
"Les fins municipales pour lesquelles un immeuble peut être acquis par...
P (block)
" "
L (block):
/ListNumbering /Decimal
LI (block)
LBody (block)
"1. Habitation; "
Si on regarde le règlement de zonage, c’est dix fois pire, tout se
trouve dans des L imbriqués à perte de vue!
Aussi, une fois qu’on a compris et correctement interpreté le très compliqué standard pour indiquer la structure logique d’un PDF (ce que ne font que partiellement les logiciels libres de PDF, à moins qu’on ait le goût de s’inféoder à Adobe), il reste qu’on doit encore extraire et traiter le contenu.
Finalement, rien n’assure que la structure sera présent à travers multiples versions d’un document, puisque le fonctionnaire qui génère le PDF doit se rappeler de cocher la case “Tagged PDF” ou “PDF/UA” en le faisant et ne pas simplement “imprimer en format PDF”, et parce que des outils de manipulation de fichiers PDF ont tendance à omettre la structure lors des transformations.
Pour cette raison non seulement est-il impossible de se fier complètement à la structure logique d’un PDF, mais il est aussi dangereux même de l’utiliser pour alimenter un modèle probabilistique. La démarche plus robuste est d’entraîner deux modèles, l’un avec les traits structurels et l’autre sans, et choisir le plus approprié selon la présence de structure ou pas.
Annotation des données (la suite)
À date, je n’ai jamais réussi à trouver un logiciel libre potable pour faire l’annotation de séquences ou étendues de texte, peut-être parce que l’annotation est un marché très lucratif - sans annotation, il n’y a aucune « intelligence » artificielle après tout!
Le plus promettant qui existe est Doccano mais j’avais jugé qu’il prendrait trop de travail pour l’adapter au cas d’usage particulier pour quelques raisons:
- Il est conçu pour annoter du texte brut ou des images individuelles. Soit on perdrait la mise en page, soit le travail deviendrait ardu à force d’annoter des centaines de pages individuellement.
- Il faudrait convertir les données dans son format préféré puis reconvertir les annotations à la sortie pour les aligner sur les données extraites du PDF.
- Son architecture est quand même assez complexe alors qu’on a vraiment juste besoin de mettre des catégories sur des lignes dans un fichier CSV…
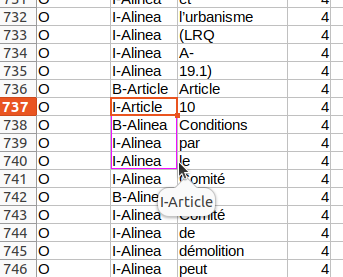
Heureusement il existe un outil bien adapter pour l’annotation de CSV, qui s’appelle tantôt LibreOffice Calc, tantôt Microsoft Excel, blanc bonnet, bonnet blanc… ça marche vraiment très bien puisqu’il se rappelle des valeurs qu’on rentre dans une colonne, alors une fois les tags (étiquettes) rentrés on n’a que taper quelques lettres, puis on peut étendre une tag pour couvrir un segment entier de texte en glissant la souris, par exemple:
Ce qu’il est important de comprendre, par contre, c’est que en tant qu’application de fiche de calcul, Calc (et Excel aussi) ont tendance a “interpreter” les données dans un CSV de façon inattendue. Alors, il faut absolument, lors de l’ouverture d’un fichier CSV, s’assurer dans le dialogue de conversion, que:
- Le jeu de caractères est réglé sur “UTF-8”
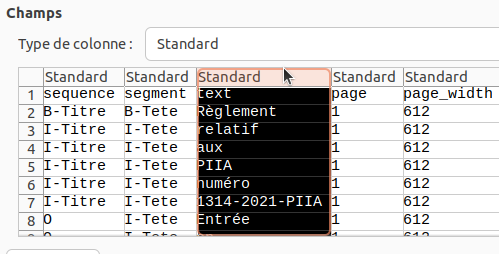
- Le type de colonne pour la colonne “text” est réglé à “Texte”
Pour ce faire, il faut dans le dialogue de conversion sélectionner la colonne en cliquant sur son titre:
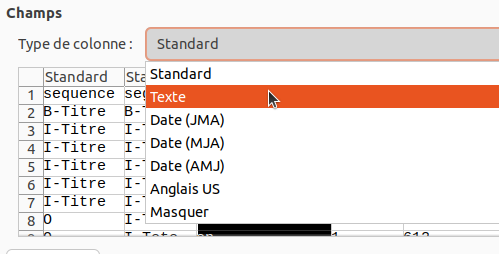
Puis sélectionner “Texte” dans le menu d’options:
Annotation et Correction avec ALEXI
Avec ALEXI on peut générer un CSV de cette sorte pour une ou toutes les pages d’un PDF. Si par exemple, on voudrait adapter le modèle d’extraction au nouveau règlement d’urbanisme durable de la ville de Prévost, la procédure est:
- Télécharger le PDF (bien sûr) - par exemple (mon préféré) le titre 6: Mobilité durable et stationnement écologique.
- Extraire un CSV préliminaire avec
alexi annotate RUD_T6_VR.pdf T6. Ceci créera les fichiersT6.pdfetT6.csv- le premier est une version du PDF original marqué avec des rectangles colorés pour les éléments (alinéas, titres, items) identifiés dans le texte, alors que le deuxième est la réprésentation CSV. - Ouvrir le CSV dans un logiciel de fichier de calcul et corriger les annotations en suivant la démarche ci-haut.
Pour revoir l’effet de changer le CSV sur les annotations, il suffit
de rouler de nouveau la commande alexi annotate mais avec le CSV
corrigé: alexi annotate --csv T6.csv RUD_T6_VR T6. On peut
également extraire le document avec les nouvelles annotations en
utilisant alexi export -o T6-html T6.pdf puis voir le HTML extrait
en partant de T6-html/index.html.
Dans un prochain billet, nous allons regarder le processus d’identification des éléments du texte ainsi que l’entraînement de modèles en intégrant les annotations corrigées.