Pour plusieurs raisons, je suis en train de quitter GitHub depuis
quelques mois. Je n’irai pas trop dans le détail, surtout parce que
ce billet de
blogue décrit pas
mal mon parcours, et je crois, celui de plusieurs autres participants
au mouvement du logiciel libre.
Disons que la valeur ajoutée par GitHub à travers les communautés de
pratique et les interactions avec d’autres humains n’est plus au
rendez-vous, surtout que ces interactions authentiques se font de plus
en plus rares. À chaque époque sa peste, j’imagine, SourceForge ayant
été rendu inutile et nuisible par la publicité malveillante et
intrusive,
et maintenant GitHub qui s’est auto-infligé un
essaim d’«agents»
automatisés.
Comme premier pas vers un avenir plus libre et durable, je me suis
donné la tâche de déposer la configuration Hugo et les codes sources
de mes sites web professionnel et
politique dans une instance
auto-hébergée de
Forgejo (le saviez-vous, le nom de ce logiciel
est en espéranto … comment savoir qu’on a affaire à un truc de vrai
geeks!)
Cela m’a donné l’opportunité d’enfin implémenter une mise à jour
automatique du site déclenchée par les mises à jour du dépôt Git, oui,
du CI/CD toi chose. En plus, c’est pas mal plus simple et sécuritaire
avec Forgejo qu’avec
GitLab - on peut tout faire
avec Podman en mode «rootless»
par défaut (rien à installer sauf Podman lui-même!)
J’ai même pris l’initiative de réécrire la documentation de
Forgejo
à ce sujet, donc allez-y jeter un coup d’œil…
Le CI est pas mal simple. Le fait d’être auto-hébergé permet
d’économiser beaucoup de bande passante, car je peux simplement créer
ma propre image Podman localement sur le server avec ce petit
Containerfile:
Par la suite, les informations d’utilisateur et mot de passe sont
enregistrées dans des
secrets
de Forgejo Actions, et je n’ai qu’à les définir dans
l’environnement pour les donner
à rclone, que j’utilise pour mettre à jour le
site avec WebDAV:
Si vous cherchez à mieux comprendre le règlement d’urbanisme de votre
ville, il est très utile d’avoir une carte interactive qui permet de
faire la correspondance entre adresses ou quartiers et zones. Des
grandes villes, qui ont de l’expertise interne en géomatique et des
abonnements coûteux à ArcGIS,
publient souvent ce genre de carte sur leur site web, par exemple
Laval,
Montréal ou
Sherbrooke. Des
petites villes… pas tant que ça!
C’est pour ça que, quand j’ai été élu au conseil à Sainte-Adèle, j’ai
créé ZONALDA, une carte de
zonage interactive simple, gratuite et libre. Cet article est la
première d’une série qui détaille la conception et l’implémentation
d’une telle carte, en commençant par la base - c’est à dire, la base
de données géomatique, qui contient les formes et emplacements de
toutes les zones ainsi que leurs identificateurs et attributs.
Obtenir un plan de zonage
Idéalement, à défaut d’une carte interactive, votre ville ou MRC
publie la géomatique du plan de zonage sur Données
Québec (voici celle de
Repentigny
par exemple) mais généralement ce n’est pas le cas. Par contre, les
villes publient presque toujours une carte de zonage sur leur sites
web, la plupart du temps en format PDF, plus souvent dans la section
des règlements d’urbanisme. On la trouve sous le rubrique
Règlements -
Urbanisme à
Sainte-Adèle, sur la page Règlementation et
Permis à
Morin-Heights, et sur la page générale de réglementation
municipale
à Saint-Calixte.
Afin d’en obtenir la géomatique sous-jacente (habituellement sous
forme d’un Shapefile) vous pouvez
aussi essayer de faire une demande d’accès à l’information. Pour les
petites villes, c’est généralement à la MRC qui il faut s’adresser -
c’est la raison qu’on voit «Source: MRC des Pays d’en Haut» sur les
plans de zonage de Sainte-Adèle et Morin-Heights.
Finalement, on peut aussi utiliser la carte publique pour reconstruire
manuellement la géomatique des zones. Pour ce faire, on utilisera le
logiciel libre QGIS, accompagné par
GIMP et InkScape et
assaisonné avec un peu de jus de bras.
Cas facile: Morin-Heights
Il faut d’abord savoir qu’un PDF n’est pas une seul et unique sorte de
fichier, et il est nécessaire de savoir d’abord à quelle sorte de PDF
vous avez affaire. Le plan de zonage de
Morin-Heights
est un très bon PDF parce qu’il est vectoriel et géoréférencé.
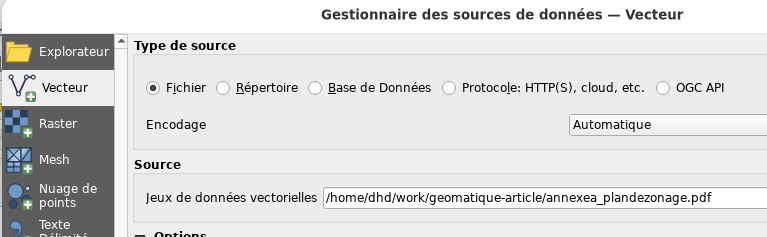
Comment le savoir? D’abord, on ouvre QGIS et on ajoute une carte de
base OpenStreetMap. Maintenant, il faut simplement essayer d’ajouter
le PDF comme couche vectorielle dans QGIS:
On voit que cette opération nous réussit à ajouter plusieurs couches
vecteur et, même si les zones ne sont pas ajoutées comme polygones,
les limites des zones sont présentes comme lignes et placées
correctement sur la carte:
Dans ce cas-ci, il ne nous reste qu’à tracer les limites de chaque
zone avec les options «accrochage» et «traçage» des outils de
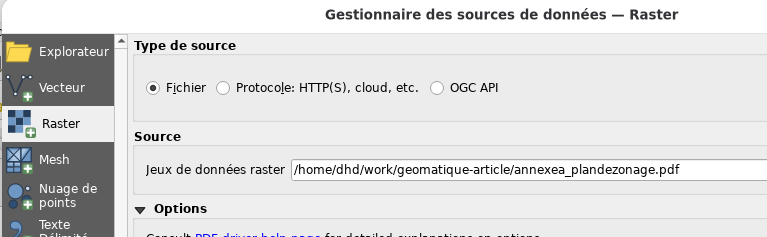
numérisation. On va aussi importer la carte comme couche
matricielle (raster) pour être capable de voir les identificateurs
de zone. Donc, il faut importer le PDF une deuxième fois, cette fois
comme «raster»:
On est prêt à créer la géomatique des zones! Pour ce faire:
Mettre la carte raster en-dessous des vecteurs dans la liste de
couches.
Créer une nouvelle couche temporaire en mémoire, avec une géométrie
de polygone et un SCN de EPSG:4326 - WGS-84. Ajouter un champ
“zone” de type texte aussi. Maintenant, cliquer avec le bouton
droit sur la nouvelle couche et sélectionnez «Convertir en couche
permanente», puis sauvegardez-la en GeoJSON.
Activer la barre d’outils «accrochage» et sélectionner le bouton
«trace» dans la barre. Très important: la fonction «trace»
n’est pas toujours capable de prendre en charge plusieurs couches à la fois.
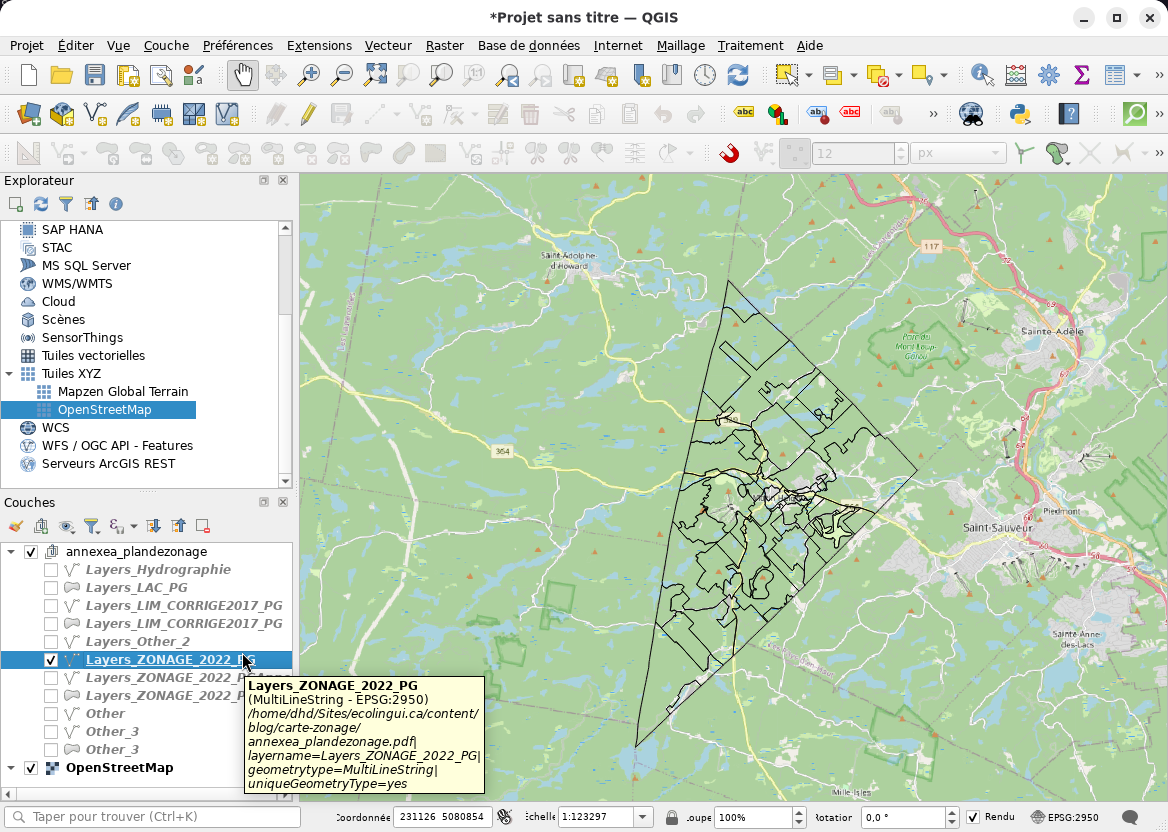
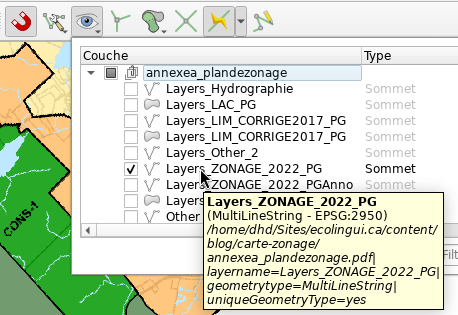
Il faut donc aussi selectionner «Configuration avancée» dans le
menu à droite de l’aimant, puis cocher seulement
Layers_ZONAGE_2022_PG dans le menu sous l’œil qui apparaît à
côté:
Maintenant vous pouvez utiliser l’outil «Ajouter une entité
polygonale» et cliquer avec le bouton gauche en suivant le contour
d’une zone. L’accrochage fera en sorte que les points seront
placés sur les limites de la zone, et la trace suivra les courbes
et autres détails. Si vous faites une erreur, utilisez la touche
«backspace» pour enlever le dernier point. Une fois rendu au point
de départ, fermer le polygone avec le bouton à droite. Dans le
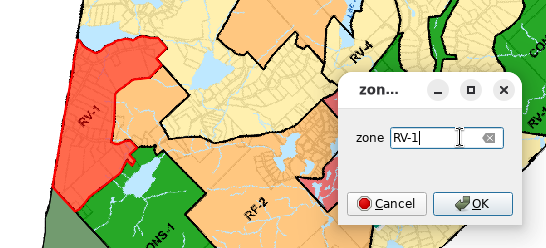
dialogue, entrez l’identificateur de la zone tel qu’indiqué dans la
carte raster:
Pendant que vous tracez, vous pouvez effacer le dernier point avec
la touche «Backspace», annuler la figure avec «Esc», ou bouger la
carte en tenant la barre d’espace en bougeant la souris. Pour
désactiver ou réactiver la trace pésez sur «T», et pour désactiver
ou réactiver l’accrochage, la touche «S».
N’oubliez pas de sauvegarder votre travail de temps en temps!
Après une demi-heure environ de traçage, vous aurez une couche
vectorielle avec des polygones pour toutes les zones de Morin-Heights,
et vous aurez aussi un fichier GeoJSON que vous
pouvez visualiser avec uMap:
Cas plus difficile: Sainte-Adèle
Ce n’est pas toutes les villes qui produisent (ou demandent à leur MRC
de produire) des fichiers PDF aussi futés. Ça se peut que vous aurez
un PDF qui est tout simplement une image matricielle, qui ne contient
que des pixels. Donc, QGIS va refuser de l’importer comme couche
vecteur:
Pire encore, cette image peut aussi ne pas être géoréférencée. Donc,
si vous l’importez comme raster, elle finira quelque part dans
l’océan, ou dans les montagnes de l’Équateur, tout dépendant de votre
SCN:
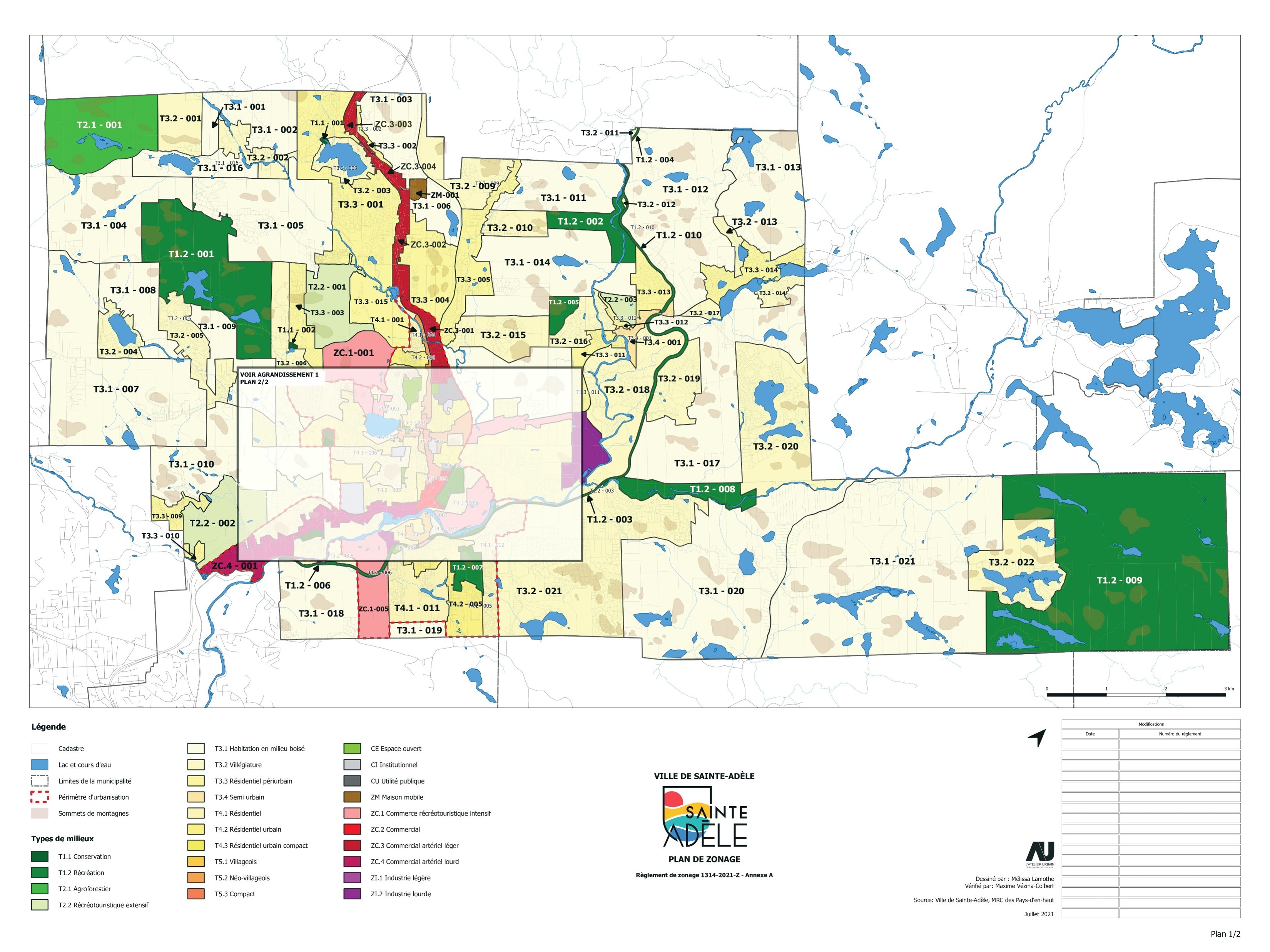
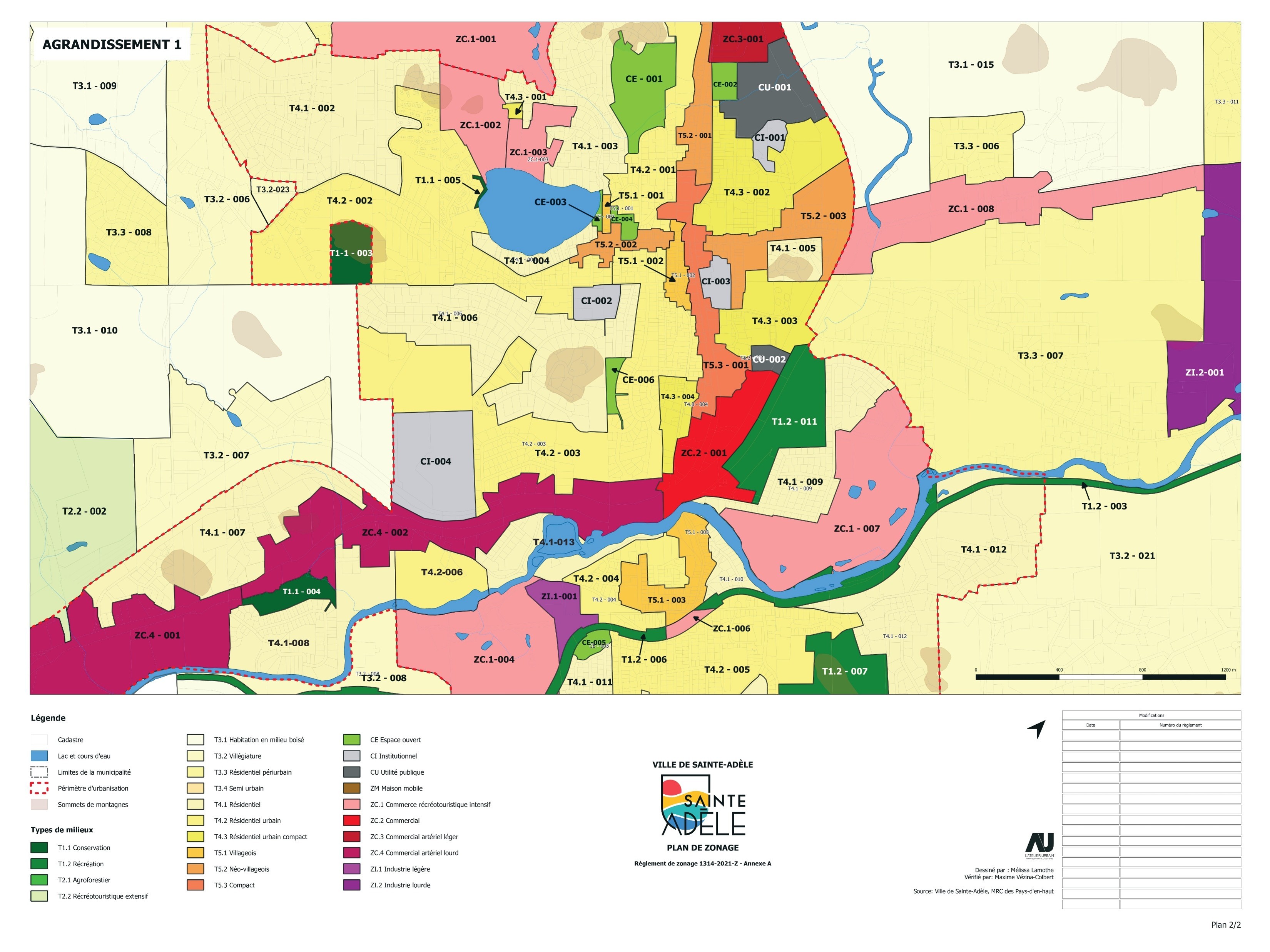
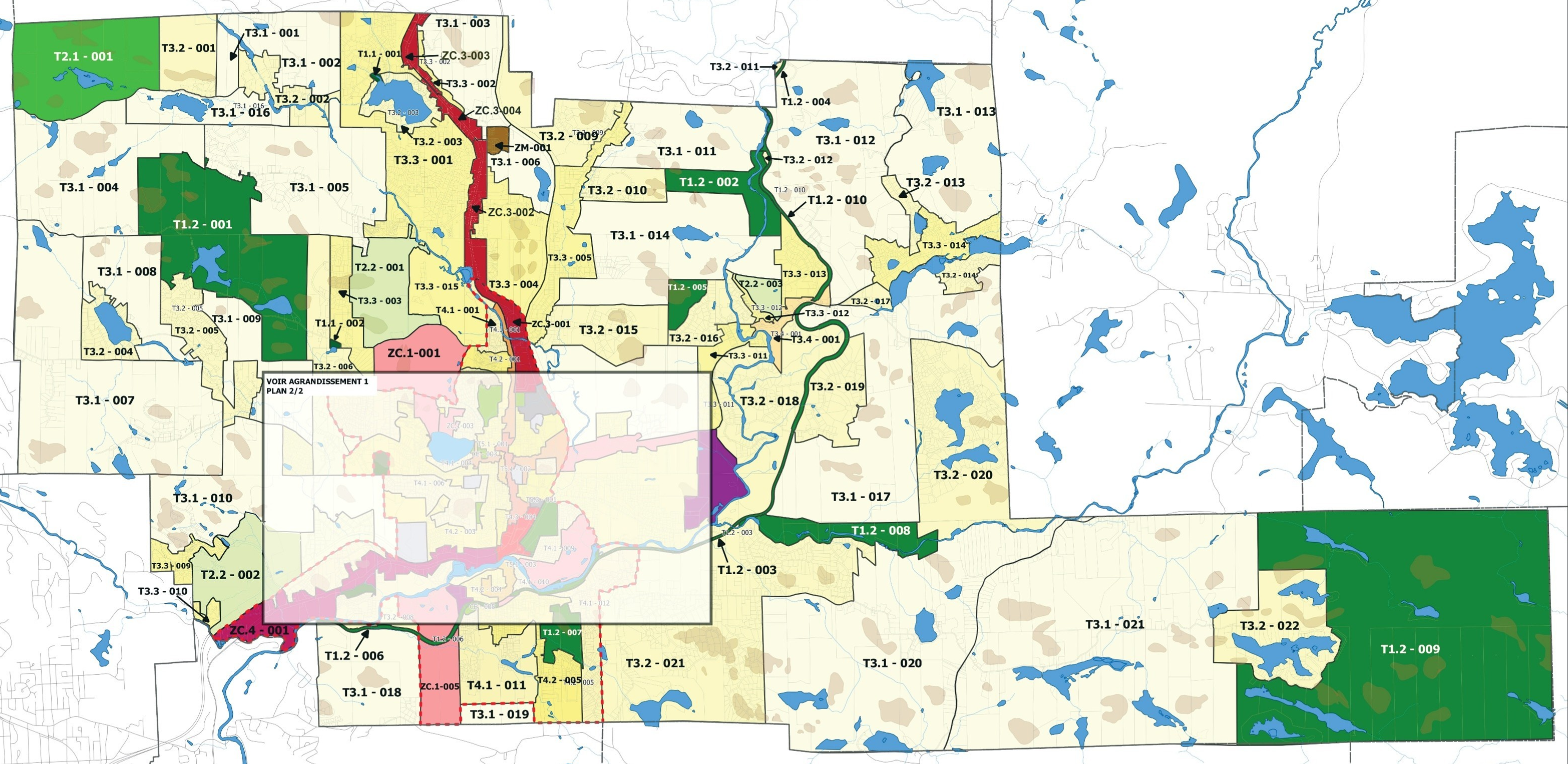
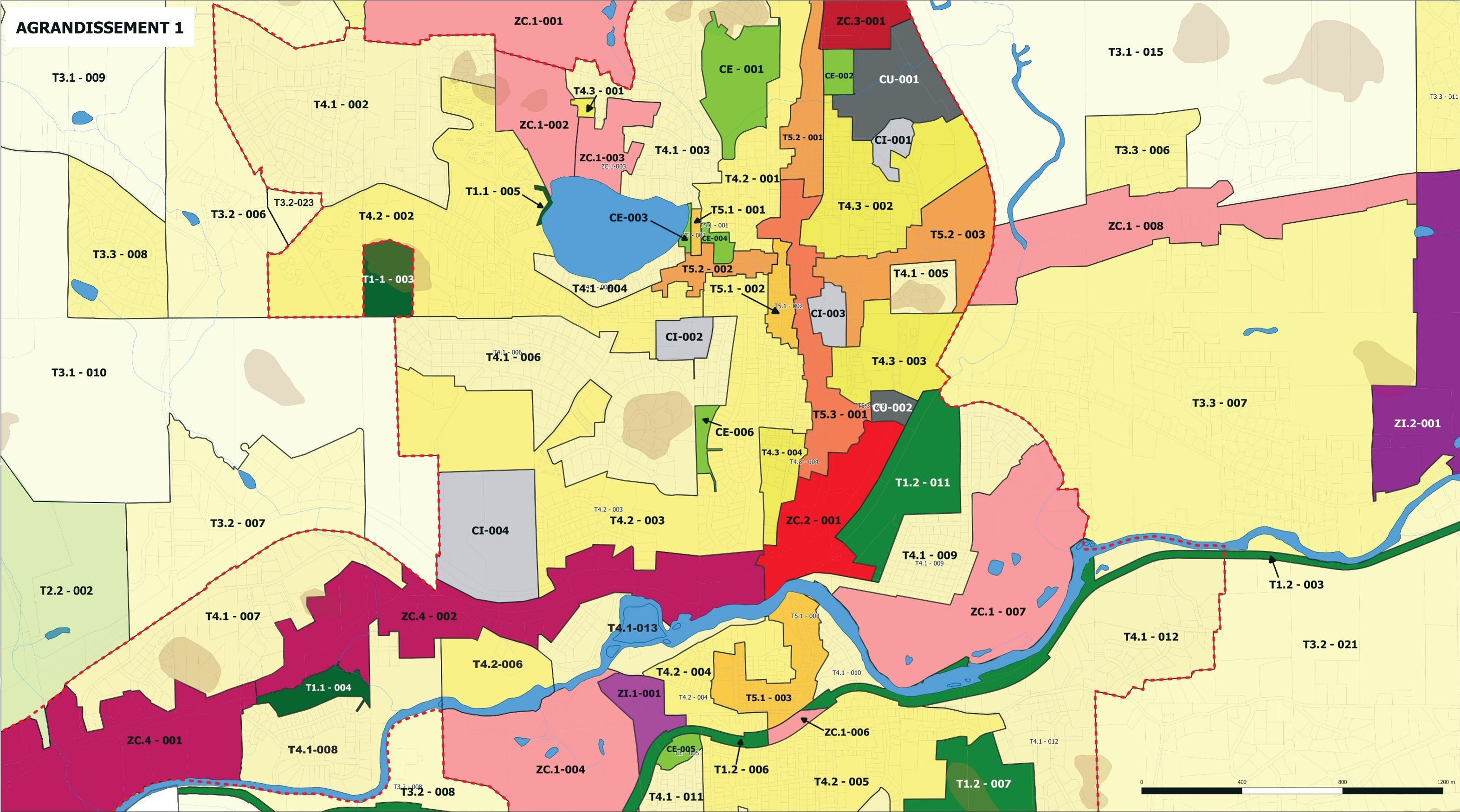
Sainte-Adèle figure malheureusement parmi ces villes moins douées en
géomatique. Qui plus est, elle publie aussi deux cartes séparées de
zonage, une pour la ville au
complet et une autre
plus détaillée pour le périmètre
urbain. Mais tout n’est
pas perdu! QGIS est très capable de faire quelque chose avec ce genre
de PDF, avec un peu plus de travail.
D’abord, on n’ajoutera pas directement ces fichiers dans QGIS comme
couche raster, car ils ne sont pas géoréférencés, mais aussi parce que
QGIS par défaut va réduire la résolution de
l’image qui les rend pas très
lisibles. C’est très courant pour des cartes en PDF d’être composées
d’une seule image matricielle, donc, on va extraire ces images avec
PLAYA-PDF:
En effet, si on regarde les fichiers tout.json et
zoom.json on constate qu’il y a bel et bien une seule et
très grande image dans chaque fichier (tout
et zoom). Étant donné qu’on aura besoin de
les géoréférencer de toute façon, on va d’abord ouvrir ces images avec
GIMP pour les découper un peu:
Ouvrir les images .jpg avec GIMP
Découper l’image juste au-delà des limites de la ville, ou aux
limites de la carte pour le plan plus détaillé
Ajouter un canal alpha (Calque → Transparence → Ajouter un canal alpha)
Exporter l’image en PNG (ou TIFF, peu importe…)
Ça nous donne tout.png et zoom.png. Par la
suite on va les incorporer dans QGIS avec la fênêtre
«Géoréférencer…» (dans le menu «Couche»). Mais, pour faire ceci, ça
nous prend des points de référence fiable, comme les limites de la
ville. Très important: N’utilisez jamais les limites
administratives dans OpenStreetMap, elles sont incorrectes! On va
alors télécharger les données ouvertes des découpages administratifs
du
Québec.
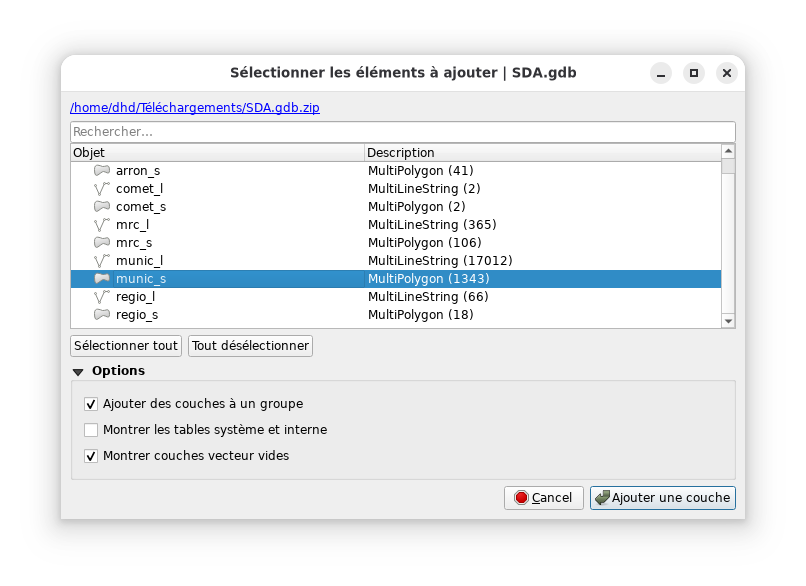
Pour rendre ça plus rapide, on n’a qu’à sélectionner l’objet munic_s:
Il est sûrement possible de demander simplement la limite d’une seule
ville avec le serveur REST, mais je n’ai pas réussi à en trouver la
documentation…
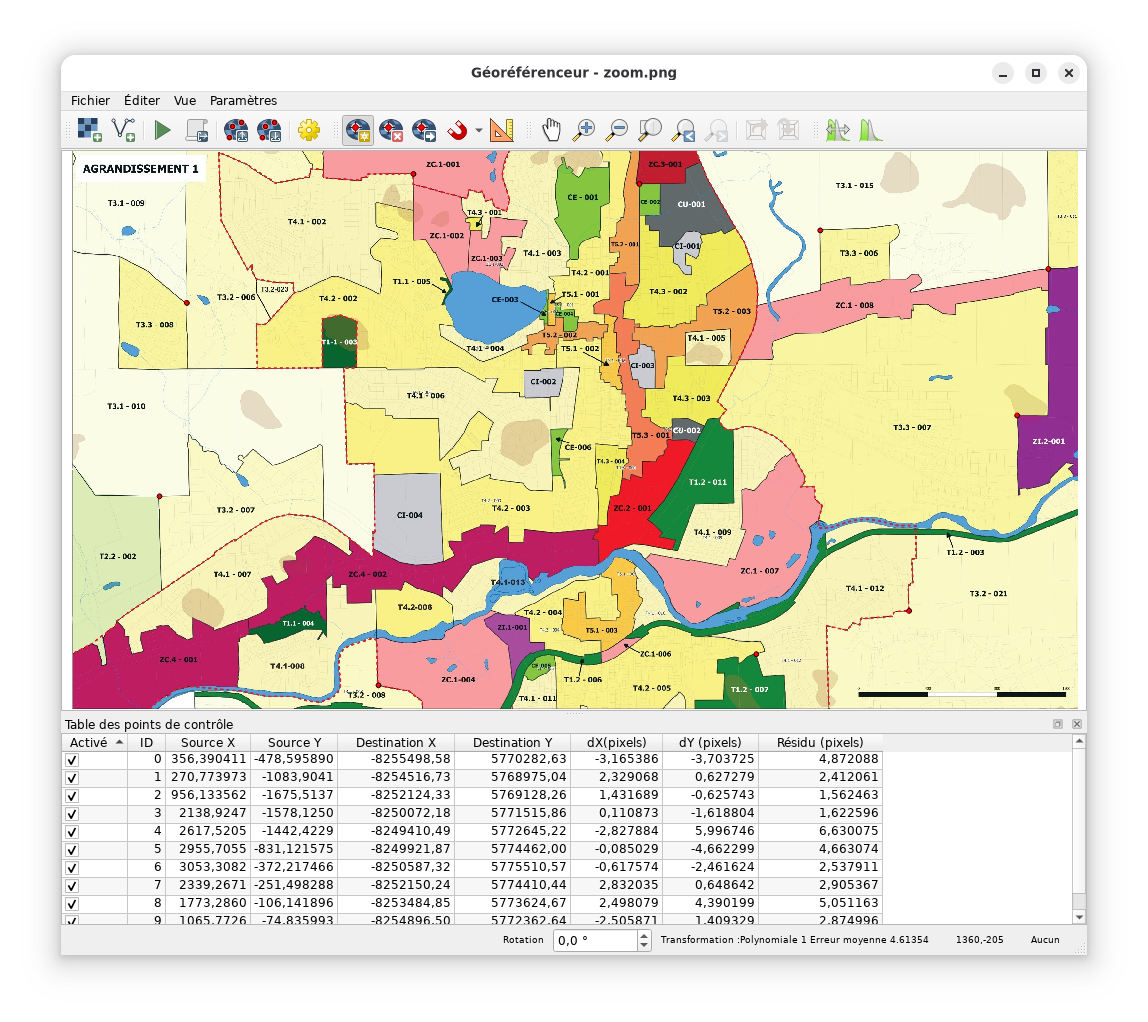
On peut maintenant géoréférencer la carte complète de la ville par
rapport aux limites administratives:
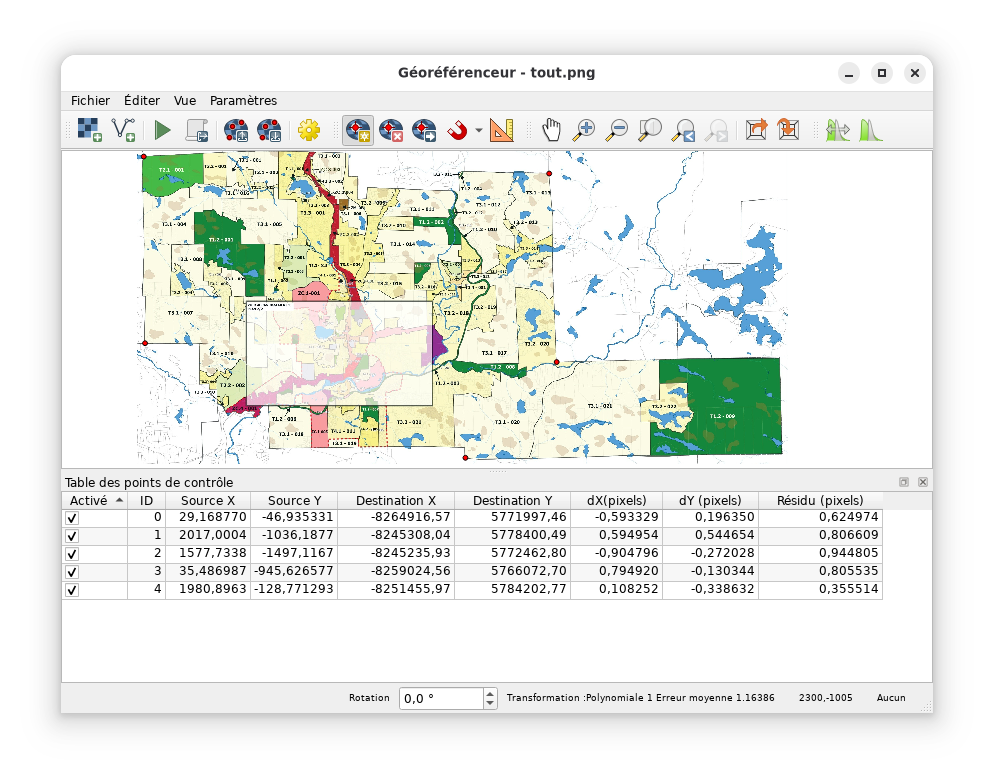
Ouvrir le géoréférenceur et ouvrir tout.png comme
raster (Ctrl+O ou Fichier → Ouvrir un raster…)
Selectionner l’outil «Ajouter un point de contrôle» et placer un
point à un point sur le contour de la ville, puis selectionner
«Depuis le canevas de la carte…»
Identifier le point correspondant sur les limites administratives.
En activant l’accrochage (icône en forme d’aimant) sur cette couche
spécifique on peut avoir un peu plus de précision.
Le coin Sud-Est de la ville ne correspond pas exactement, alors il
vaut mieux ne pas l’utiliser. Ces 5 points suffisent:
Modifier les paramètres de transformation pour utiliser
«Polynomiale 1» et «Cubic» et définir le nom du fichier en sortie,
puis débuter le géoréférencement.
En superposant de nouveau la couche des limites administratives, on
confirme qu’on a un très bon alignement:
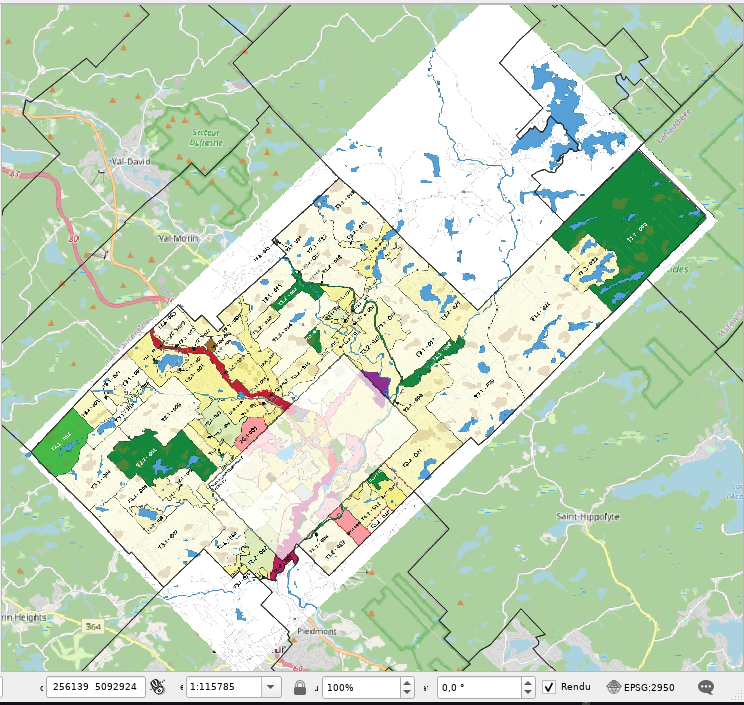
Pour la carte d’agrandissement, on fera un processus semblable, sauf
que les limites de l’agrandissement ne sont pas exactes, donc il vaut
mieux définir des points de contrôle sur les points saillants des
zones, au lieu des limites de la carte:
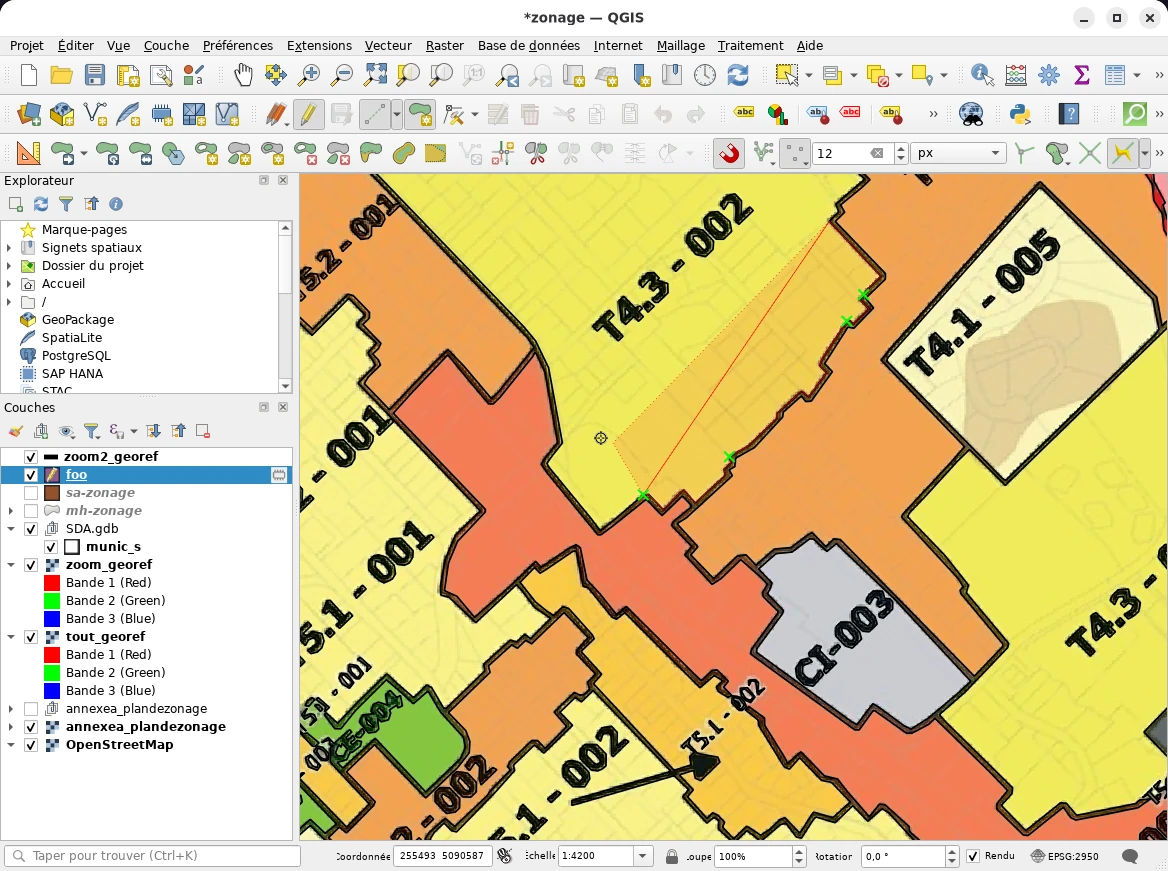
Après le géoréférencement, on peut réduire l’opacité de la nouvelle
couche pour confirmer que les zones sont bien alignées, bien qu’il y
ait un petit écart sur le haut de l’agrandissement:
Ça nous fais une très belle carte, mais… il faut quand même tracer
les zones. Pour celles qui sont plutôt rectiligne, et collées sur les
limites de la ville, ce n’est pas trop difficile, mais plusieurs ont
des formes très complexes. Il serait donc très utile de pouvoir
extraire au moins quelque chose de vectoriel sur lequel on pourait
accrocher pour faciliter le traçage.
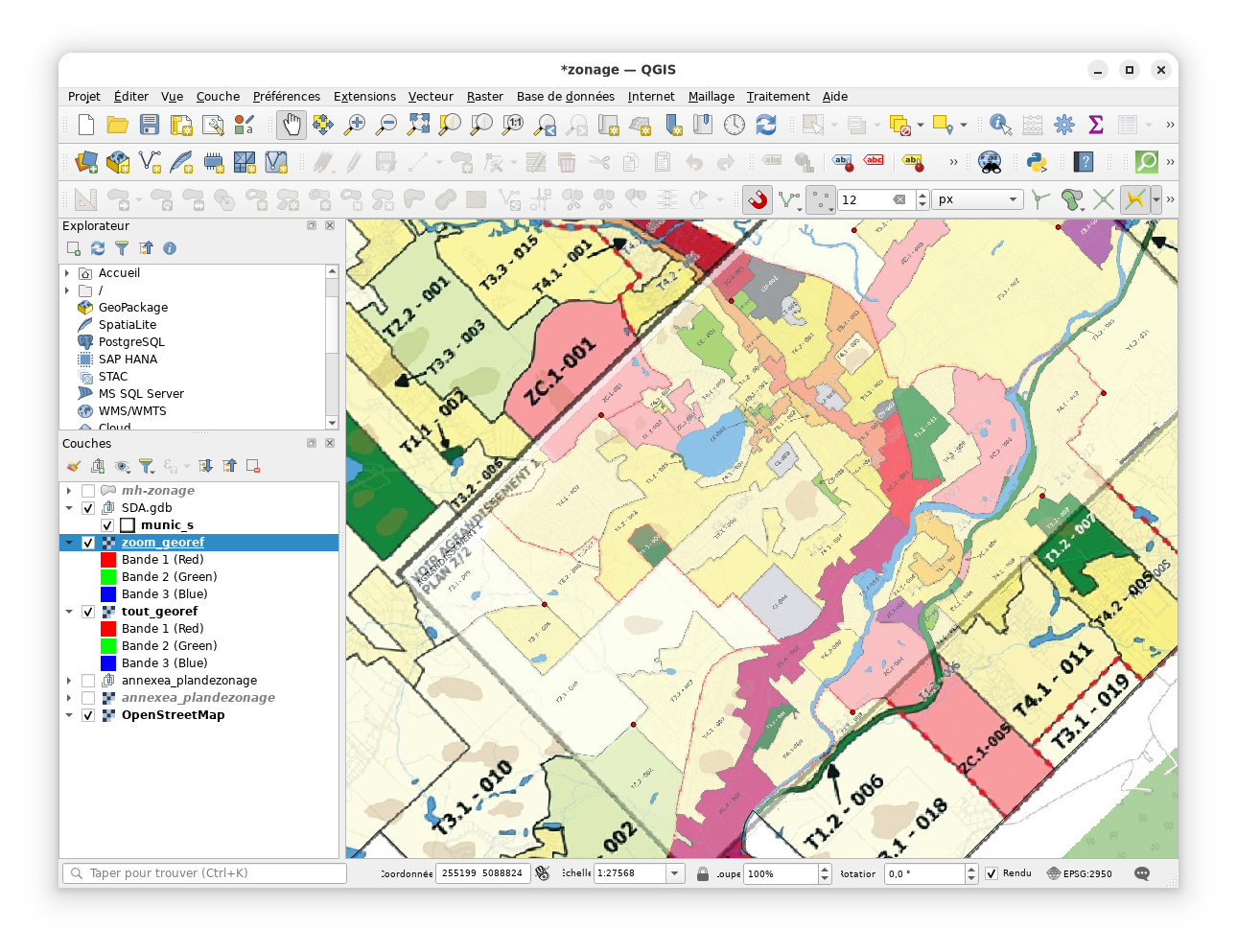
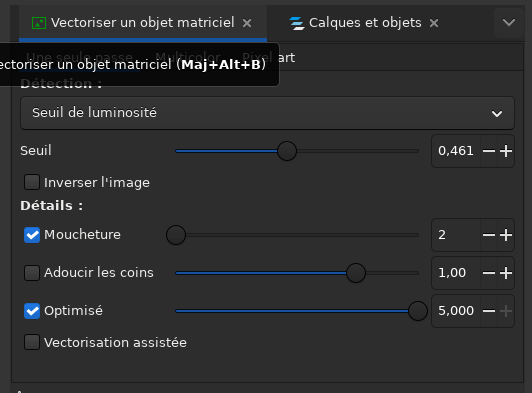
Auto-traçage et géoréférencement
Pour obtenir une couche vectorielle qui nous aidera à guider le
traçage, on peut ouvrir nos fichiers PNG avec
InkScape, puis sélectionner «Chemin →
Vectoriser un objet matriciel…». Pour l’agrandissement, des
paramètres comme ceux-ci fonctionnent:
On peut masquer (ou carrément supprimer) l’image matricielle de base
pour voir que ça nous donne déjà quelque chose un peu plus potable:
Après avoir detecté les lignes, il faut sauvegarder le projet en
format DXF. Pourquoi ce format? seul QGIS le sait c’est parce que
c’est le format utilisé par AutoCAD pour des plans d’implantation, qui
ont souvent besoin d’être géoréférencés! Heureusement, ça peut aussi
très bien servir pour d’autres sortes de dessins vectoriels. Par la
suite on peut refaire le géoréférencement, mais en ajoutant les objets
dans ce fichier comme vecteur:
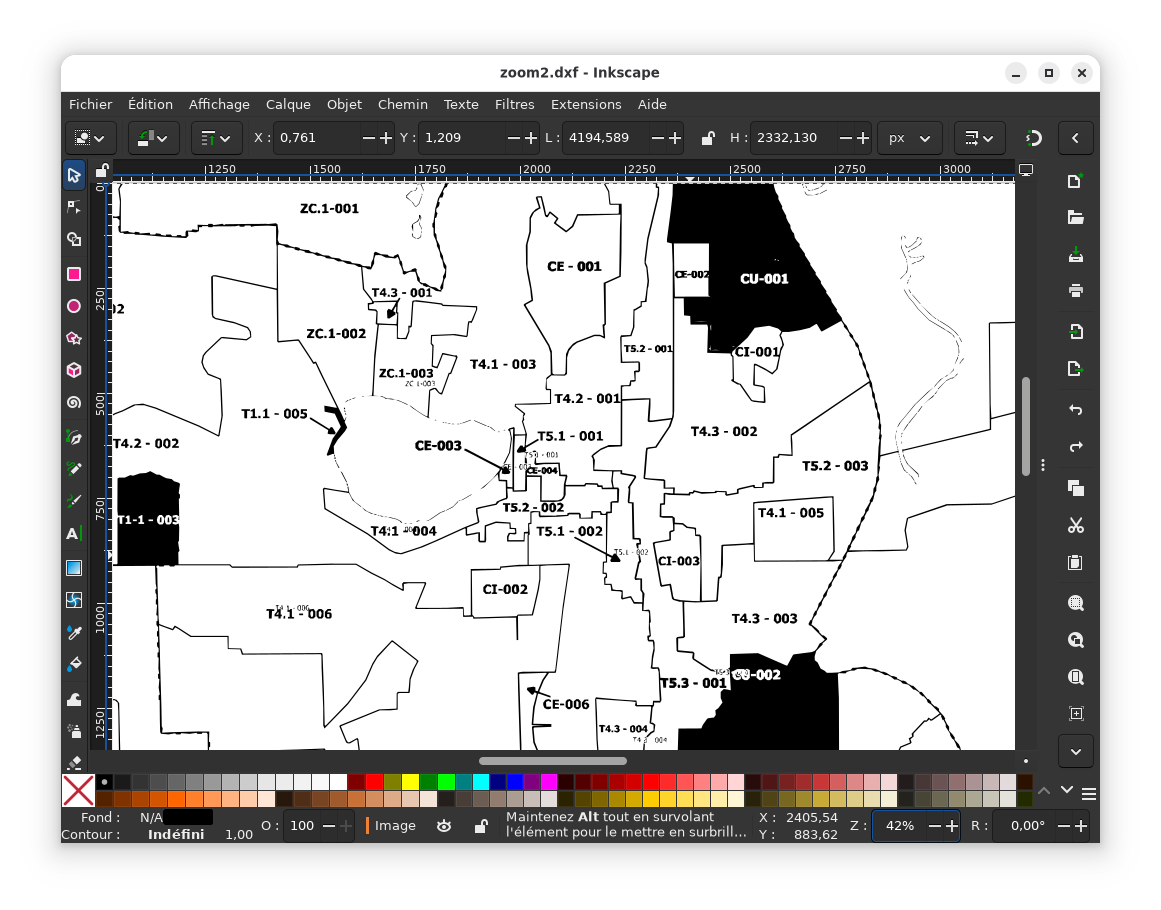
La principale difficulté à tracer en utilisant ces vecteurs, c’est que
parce que les lignes dans l’image originale sont épaisses, on se
retrouve avec deux traces pour chaque ligne. Il faut aussi faire
attention aux flèches et textes qui se font aussi tracer (la touche
«T» est très utile).
En fin de compte, ça nous permet d’avoir des pas pires resultats, mais
ça prend du temps:
Par la suite, nous allons regarder comment géolocaliser des adresses
pour les situer dans une zone, et comment réparer la base géomatique
au cas où des géométries invalides empêchent ceci de fonctionner.
QGIS est muni des «outils de numérisation avancés» qui permettent de
nettoyer les données qu’on aura créées en traçant.
Il est aussi possible d’améliorer l’extraction de figures en détectant
automatiquement les étiquettes textuelles des zones et les enlever de
la figure… on regardera ça dans un deuxième temps!
Si vous voulez fouiller dans les entrailles d’un document PDF pour en
extraire des metadonnées, des images, et même du texte, j’ai des
superbes logiciels libres pour vous:
PLAYA-PDF et
PAVÉS. Si vous voulez savoir
comment je suis arrivé là, continuez à lire. Et si vous avez besoin
d’un consultant pour vos besoins d’intelligence documentaire je suis
bien sûr disponible pour des contrats de toute sorte!
«Vous n’êtes qu’un paquet d’objets indirects!»
Comme vous savez peut-être (ou pas), je suis chercheur en
linguistique
informatique
de formation et de
métier.
En 2021, fraîchement élu conseiller municipal dans une ville du grand
St-Jérôme que je ne nommerai pas, j’ai quitté mon poste de
scientifique principal chez une compagnie (que je ne nommerai pas non
plus), maintenant division de Microsoft, car il était impossible pour
moi de servir deux maîtres travailler à temps plein à Montréal
tout étant un élu efficace et à l’écoute. La chose municipale me
semblait aussi, à l’époque, bien plus intéressante que le raffinement
des modèles d’apprentissage automatique pour la compréhension du
langage naturel.
Entre-temps, il s’est passé des choses…
Un effet secondaire de ce changement de carrière plus ou moins bien
avisé est que je suis devenu (en tout humilité) expert en analyse et
manipulation des fichiers PDF, et ce, de la manière habituelle des
informaticiens de mon genre: j’ai parti un projet de logiciel libre.
Pourquoi?
Lorsqu’on regarde les défis de gestion des documents dans
une ville ou autre organisme, on se rend très vite compte que malgré
les grands efforts des promoteurs de ODP, OOXML, HTML et autres
formats universels, en fin de compte, le PDF, c’est la lingua franca
de tous les échanges documentaires. C’est la triste conséquence de la
domination du bureaucratique par nul autre que Microsoft, dont les
logiciels font exprès de multiplier les incompatibilités non seulement
avec d’autres produits (libres ou
pas), mais ne sont souvent
même pas compatibles entre eux-mêmes.
Comment?
J’avais des critères pour l’outil que je voulais utiliser, qui ne
correspondaient pas à l’état actuel des logiciels disponibles:
Licence libre et permissive (du genre BSD, MIT).
Écrit en Python et portable entre différentes plateformes.
Interface conviviale pour le programmeur.
Accès direct aux structures interne du PDF, avec la capacité
d’extraire non seulement du texte mais les éléments de mise en page
et les metadonnées.
Rapide et efficiente, autant que possible (c’est un peu en conflit
avec #2 mais bon).
Le logiciel qui se rapproche le plus de ces critères à l’époque était
pdfplumber, un très bon
logithèque qui satisfait néanmoins aux critères 1, 2 et 3! J’y ai
même contribué un module pour l’extraction des arborescences de
structure logique. Par contre, l’efficacité n’est pas trop au
rendez-vous, surtout parce que pdfplumber, comme d’autres projets
populaires dont sa logithèque sous-jacente
pdfminer.six, doit
analyser chaque page au complet et construire toutes les structures de
données avant de retourner des informations demandées.
De paresse et de parallélisme
C’est surtout ça l’innovation de PLAYA-PDF: il est
«paresseux»,
ne traitant que les informations nécessaires pour extraire
l’information que vous désirez. Si vous, par contre, vous êtes
paresseux·se, il possède aussi un interface qui peut convertir les
metadonnées d’un PDF en
JSON, et ce, très
rapidement:
with playa.open(path) as pdf:
json.dumps(playa.asobj(pdf))
L’autre élément clé, PLAYA-PDF prend en charge plusieurs cœurs de
processeur en
parallèle,
et ce, de manière très conviviale:
with playa.open(path, max_workers=4) as pdf:
texts =list(pdf.pages.map(playa.Page.extract_text))
Par-dessus la PLAYA, les PAVÉS!
Parce que les objectifs de PLAYA-PDF sont surtout l’efficacité et
l’absence de dépendances sur d’autres logiciels, il ne prend pas en
charge des tâches de plus haut niveau, nécessitant de l’imagerie, des
heuristiques ou des modèles d’apprentissage automatique.
Pour cette raison je suis aussi en train de construire
PAVÉS qui prendra de plus en plus
en charge:
L’analyse structurelle et textuelle des PDF, dont le traitement des
tableaux et l’extraction d’unités logiques de texte.
La
visualisation
des objets dans un PDF ainsi que la conversion des pages en images.
Ce deuxième logithèque est encore en chantier mais sert déjà à faire
l’analyse nécessaire pour alimenter mes projets tels que
ZONALDA et
SÈRAFIM.
Conclusion
Si vous faites partie du petit nombre de gens auxquels ça intéresse je
vous invite à l’essayer! J’ai publié entre autres de la
documentation et quelques carnets
Jupyter qui
démontrent la fonctionnalité.
Vous pouvez bien sûr aussi contribuer au développement sur
GitHub (notez qu’il se peut que je
le déplace bientôt vers Codeberg ou autre
hébergement indépendant et au-dehors des États-Unis, mais il restera
toujours disponible sur GitHub).




{kind=link}
{kind=link}
{kind=link}
{kind=link}